

英特尔Intel Vision 2024大会于4月8日-9日在美国亚利桑那州凤凰城登场,会中宣布推出Gaudi 3 AI加速器,由台积电5nm制程代工,挑战Nvidia在AI领域高市占率,企业生成式 AI带来新选择。
英特尔的Gaudi 3与Nvidia的H100相比,支援AI模型执行推理快了50%,训练大模型则比H100快了40%。 英特尔更指出,Gaudi 3的表现将与Nvidia的H200比肩,在某些领域的表现甚至会优于H200。
再者,英特尔Gaudi 3在Llama上做测试,可有效地训练或部署AI大模型,包括文生图的Stable Diffusion和语音辨识的Whisper等。
英特尔Gaudi 3加速器将于2024年第二季,提供OEM通用基板和开放加速器模型(Open accelerator module, OAM),2024第三季全面上市,包括戴尔科技、慧与科技(HPE)、联想和美超微 等,都将采用Gaudi 3。
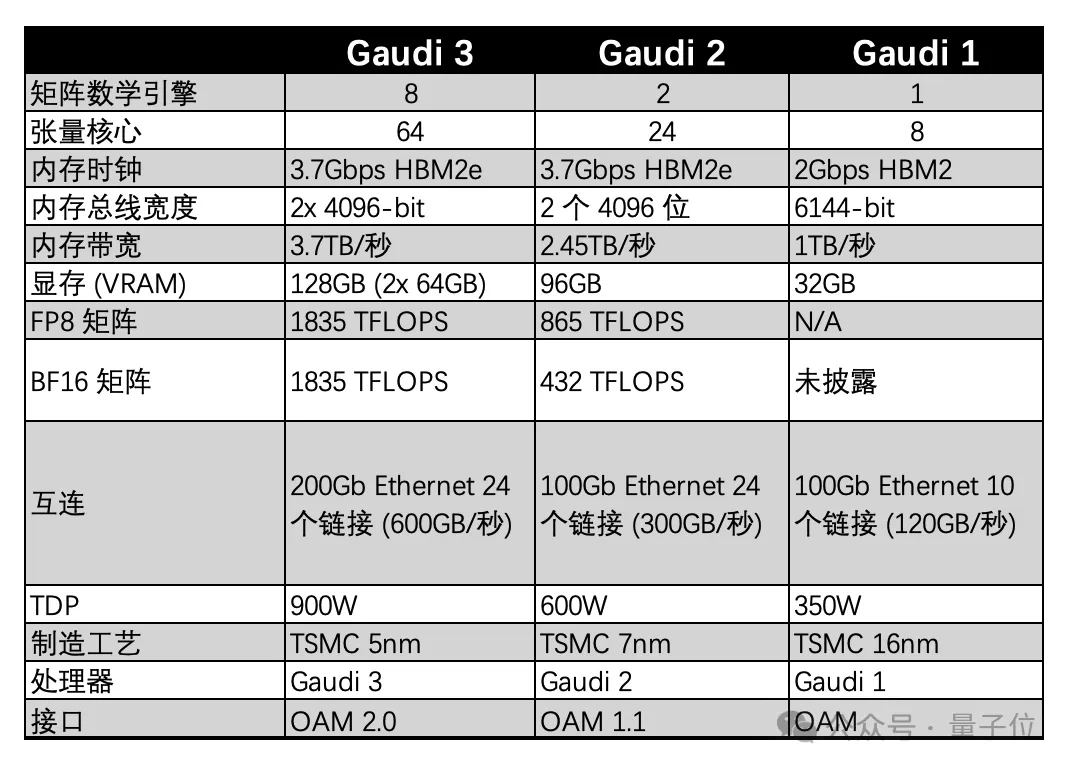
Gaudi 3加速器的主要特点:
AI专用运算引擎:Intel Gaudi 3加速器专为生成式AI运算打造。 每台加速器都有专属的异质运算引擎,由64个AI自订和可编程TPC和8个MME组成。 每个Intel Gaudi 3 MME皆能执行64,000个平行运算,运算效率极高,擅于处理复杂的矩阵运算,这也是深度学习演算法的基础运算。 此独特的设计大幅提升平行AI运算的速度和效率,并支援多种资料类型,包括FP8和BF16。
提升内存容量,满足LLM容量需求:Intel Gaudi 3搭载128 GB的HBMe2内存容量、3.7 TB的内存带宽和96 MB的on-board静态随机存取内存(SRAM),能够在更少在的Intel Gaudi 3 上,提供处理大型生成式AI资料集所需的足够内存,且特别适用于大型语言和多模态模型。
为企业提供生成式AI高效系统扩充:每个Intel Gaudi 3加速器皆整合24个200 GB的以太网端口,提供灵活的开放标准网络,实现高效扩充,以支援大型运算集,并克服专有网路 架构的供应商限制。 Intel Gaudi 3加速器实现单一节点到上千节点的高效扩充,以满足生成式AI模型的广泛要求。
开放产业软件提升开发人员生产力:Intel Gaudi软件整合PyTorch框架,并提供基于Hugging Face社群的优化模型,是目前生成式AI开发人员最常用的AI框架,让生成式AI开发人员能够在高度在抽象 层上进行操作,提升易用性和生产力,并可轻松地将模型转移到不同硬件类型上。
Gaudi 3 PCIe:Gaudi 3高速PCIe附加卡是全新产品,外型规格专为实现高效率并降低功耗设计,适用于微调、推理和检索增强生成(RAG)等工作,配备功率600瓦的标准( Full-height )封装,128GB的记忆体容量,且带宽达到每秒3.7TB。