
连于慧 2025.8.3
曦智科技主要有两个产品线,一个是光计算产品线,另一个是光互连产品线。选择在光互连爆发的时间点上,这是曦智第一次针对光互连产品线上,系统性的揭露产品进展与技术细节。

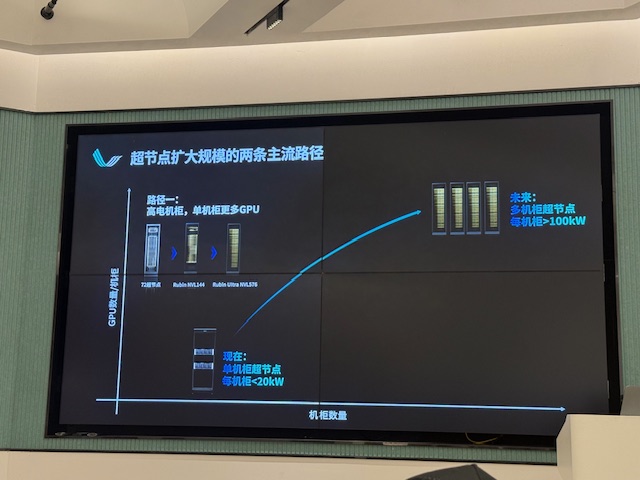
超节点的概念是什么? 英伟达去年发布的NVL72超节点系统,在GPU间互连是通过NVlink以及NVSwitch。其与传统通讯和网络不同点在于,带宽密度特别高,传输的延迟特别低。它把72张英伟达GB200GPU,全部通过NVlink的方式,以非常高的带宽和低的延迟连接在一起,形成72卡超节点,起名叫NVL72。相比于传统,把一模一样的芯片和卡组成传统单机8卡服务器,再把单机8卡服务器通过传统网络互连的方式,9台连在一起。因为两台算力是一样的,都是72颗GB200英伟达芯片,所以可以拿来对比,唯一不同点在于连接方式。 NVL72是高带换、低延迟网络,而9个NVL8对应的是传统网络连接方式。
它们的性能在这里面的对比,对于用户来讲不需要非常高的响应,如果是非常低的响应情况,不需要跨单机8卡互连,整体吞吐量是比较接近的。当模型做得越来越大,以及客户对于响应度的要求越来越高。比如输入一个问题,用户会希望大模型更快回复,它开始要求超过单机8卡服务器之间的GPU也需要高带宽通讯。在那种情况下,NVL72超节点的优势会凸显,高于传统网络互连。当每一个用户TPS超过200的时候,我们会看到一模一样的算力,但是超节点吞吐量可以比非超节点提升3倍以上,这是超节点的概念。

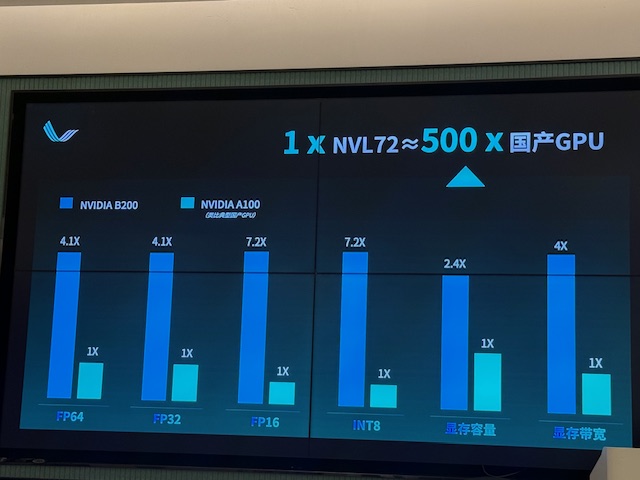
沈亦晨表示,去年提倡超节点时,大家对这概念还很陌生,现在国内几乎所有AI芯片、服务器厂商开始拥抱超节点,该趋势已确立。这里带来另外一个问题,NVL72里面的芯片是采用最先进公艺的GB200。如果是英伟达的A100,大概可以与7纳米的国产GPU算力相比。如果比较英伟达的B200与A100在单芯片计算能力上,纯计算能力可以提高5~10倍。 72张NVL72的GB200大约等于500张国产GPU的计算能力,也就是一个NVL72超节点,哪怕要匹配它的计算能力也需要500个国产GPU,这是在制程上面没有办法进一步突破的前提下。
另外一个问题是,现在国内绝大部分数据中心用到的还是非超节点方案,传统的单机8卡+RoCE网络。我们可以选择完全跟随或者复制美国英伟达道路,把更多GPU塞到机柜里面去,GPU间通过短距离铜导线连接起来去做超节点,但很难继续把500个GPU塞到一个机柜里去,不管是从功耗、散热,包括体积在内都是有限制性的,因为高带宽数据在铜导线里传,只能传1~2米的距离,在这个距离内没有办法放下这么多GPU。
沈亦晨近一步分析,英伟达下一代的Rubin是用3纳米工艺,再往后2纳米的工艺,我们需要塞到一个机柜内的量不可能永远跟得上,所以这里就必须开拓第二路径,跨机柜的带宽互连能力,才有可能追赶上,甚至超越美国GPU密度。 跨机柜往往超过1米的距离,只有一种方案就是用光进行互连,而不能继续沿用原来的铜导线方案。这边涉及到GPU直接出光,然后做跨机柜的长距离互连,在我们现在看来是必经的一条路径。最终未来国内超节点方案,首先每个机柜内会尽量放更多算力,然后会有多个机柜通过光互连的方式连接成一个超节点。
他表示,现在面临的问题是,我们没有办法再次继续原样复制美国完整技术路线,然而我们在互连能力、光芯片能力上,其实并不受限制,这会催发我们自主创新开发出一些革命性“交通工具”,以及革命性的“交通调度系统”,以此应对现在特殊的情况。 首先,把光互连相比于电互连,光互连比喻成轨道交通,电互连更像是公路交通。轨道交通相比于公路交通,一来距离可以传得更远,其次是速度有机会做得比公路交通更快,并且有自己独特的网络体系。光互连技术已经存在20年以上,在30年前发明光纤,广泛应用到长距离通讯里面,就像轨道交通也已经存在50年以上。
说一下两个特点,第一个是光电转换芯片往往会距离GPU较远,现在光模块都是存在于数据中心交换机里面,它与GPU之间至少有1米以上的铜导线距离。如果我今天要去坐轨道交通,我得从这边跑到虹桥机场,或者更远跑到杭州火车东站才能坐上火车,中间这段传输延迟是非常大的。我们需要提升单通道互连带宽,还要提升通道的密度和数量,这就催生新的光电融合技术,也就是后面讲的三块,近封装/板载光学技术,把光电转换芯片从交换机上直接放到GPU板卡上,这样距离就从1米缩短到10厘米的距离,互连密度也能提高,再把DSP芯片去掉,这样能减少GPU与GPU之间的通讯延迟。
这一代的近封装光学,是目前已经批量落地的一套互连方案,也是我们目前看到唯一通过NPO方式连接的GPU超节点,下一个阶段就是最近炒得比较火的共封装光学,进一步把光电芯片到GPU,从10厘米级别距离缩短到1毫米的距离,直接把光芯片和电芯片放在一个封装里面,好处在于我们可以进一步增加互连带宽,只需要把电信号传1毫米就可以了,带宽能再进一步提升3倍左右的带宽,同时可以进一步减少传输的延迟。这次在WAIC大会,曦智也展示了一款与国内GPU公司,应该也是全球第一次实现Demo,把一个GPU芯片通过短距Serdes,只能传1毫米的Serdes,直接以共封装的方式把信号在GPU上就转换为光信号直接连出来。
而最终的光互连方式,应该是光芯片和电芯片在同一颗芯片,称为3D共封装方案,现在美国也有公司在做。概念类似楼下直接就是高铁站,我们把光芯片和电芯片直接堆叠在一起,直接进行数据传输,预计5年内能实现。

沈亦晨表示,希望通过近封装、共封装,以及最终3D共封装光电融合的方式,大大增加单芯片带宽,目标把单芯片带宽提高到2T每毫米,一颗芯片最终做到100T量级,今天可以做到2个T的量级。另外通过用光来代替电去做互连,把超节点内的芯片数量从8颗提高到500颗,两个叠加起来,我们在一个超节点内的总带宽可以比今天单机8卡的超节点提高3个数量级。如果能用3D共封装方案,可以在3个数量级上再上一个数量级,达到4个数量级超节点总带宽的提升,这是国产芯片的趋势,用大量带宽连大量芯片创造同样的算力。
第二个重要的技术,当我们把它从公路系统,发明一种新的交通系统(铁路),连得节点GPU数量越来越多以后,必须面对的问题是,在不同轨道或者不同光互连光纤中的调度能力,因为不可能是1000张GPU永远都是以一种连接,所以需要通过调度能力调度如此复杂的网络。这也是我们最近发布的光交换技术。
怎么比喻光交换和电交换的区别?电交换就像一辆辆小汽车,每一个信号都可以在电的交换机上选择往左或往右,但是在这种情况下,整个交换容量或者交换速率基本上取决于电交换芯片本身运算能力,也就是红绿灯的能力,在特别大的超节点网络上比较容易造成堵塞。
现在不同牌子的小汽车司机就像国内不同的GPU都是follow不一样的互连协议,好比每个司机对于红灯代表停还是走,可能都是有不同的理解,没有办法把多个厂商GPU通过同一种交换芯片,让它起到互连的效果,基本上每个GPU都要定制一颗交换芯片,以覆盖互连协议,这也是现在国内面临的一个困境。
目前好的电交换芯片都是用最先进工艺,但国产受到工艺节点限制的挑战。如果都用光互连,其实大家都已经上了轨道交通,何不尝试一种直接能在铁轨间进行切换的交换方式,直接连接光的通道。因此,曦智开发了光交换系统芯片,这次在WAIC上发布全球第一款分布式、用硅光技术呈现的光交换芯片,可以通过中央信号控制调配所有光纤,让光信号在波导之间进行信号的切换,这应该是全球独创的技术。
另外,把几百个GPU卡连成一个超节点以后会碰到一个问题,如果一个GPU坏了,整个超节点都会需要下线,随着超节点越来越大,有一个GPU会坏的概率成倍增长,所以,能不能在任何一个GPU坏的时候,能迅速把一个好的冗余GPU给协调到超节点内,能够继续运行。所谓传统电的插拔方案,每次坏了得重新插光纤,在光交换能力后,所有坏了的GPU可以在毫秒时间内直接把一个好的GPU给切换上去,可以大大减少由于冗余带来的成本增加。